Anthropic just shipped 10 AI agents for finance teams. Here's what they actually do — and what they still can't replace.

On May 5, 2026, Anthropic walked into an invite-only briefing in New York and announced something that sent FactSet stock down 8.1% in a single session: ten pre-built AI agent templates designed to do the work of a junior financial analyst. The agent code is open-sourced on GitHub.
The market reaction was immediate and pointed. Morningstar reversed early gains and fell more than 3%. S&P Global and Moody's came under significant selling pressure. Analysts drew a straight line: if an AI can read an earnings transcript, build a comparable company analysis, and reconcile a general ledger, what exactly are financial data terminal providers selling?
That is the right question to be asking. But the answer is more complicated than a single-day stock move suggests. A 64% benchmark score — Anthropic's headline number — means something very specific, and what it means is not what most headlines implied.
This post goes through all ten agents, what the benchmark actually measures, where the technology delivers real value today, and which finance tasks remain legally and practically out of reach for AI in 2026.
What Anthropic Actually Launched
The ten agents split into two groups: research and client coverage agents, and finance and operations agents. Each bundles three components — domain-specific workflow instructions, governed data connectors, and focused sub-agents that can be chained together.
Eight new data connectors were announced alongside the agents: Dun & Bradstreet, Fiscal AI, Financial Modeling Prep, Guidepoint, IBISWorld, SS&C IntraLinks, Third Bridge, and Verisk. Moody's simultaneously launched an MCP app giving Claude access to data on over 600 million companies. Microsoft 365 integrations — Claude add-ins for Excel, PowerPoint, and Word — shipped on the same day, with Outlook to follow.
The agents are deployable via Claude Code, Claude Cowork, or Managed Agents — the last option enabling scheduled, autonomous runs with a full audit log in the Claude Console so compliance and engineering teams can inspect every tool call and decision.
Research and Client Coverage Agents
Pitch Builder — creates target lists, runs comparable company analysis, and drafts pitch books. This is the research assembly work that consumes the first two years of an investment banking analyst's career: pulling 10-Ks, formatting comps tables, structuring the narrative arc of a pitch. Atte Lahtiranta, Head of Core Engineering at Citadel, described analysts using it to "build and update coverage models, separate signal from noise, and pressure-test their work, all with a step-change in efficiency."
Meeting Preparer — assembles client and counterparty briefs before calls and meetings. The task is well-defined and document-heavy — exactly where retrieval-based AI performs best.
Earnings Reviewer — reads transcripts and 10-Q/10-K filings, updates financial models with new actuals, and flags guidance changes versus consensus estimates. Will England, CEO of Walleye Capital — a roughly $10 billion AUM hedge fund — noted their internal version "dramatically speeds earnings analysis." A senior analyst covering forty companies spends a minimum of four hours per company during a four-week earnings season. That is 160 hours of earnings work per quarter from a single analyst. Even a 40% reduction in that time is material.
Model Builder — creates financial models from filings and data feeds. The agent reads structured data sources and builds the skeleton of a model — a task that is tedious but well-documented enough that AI handles it reasonably well when the source documents are clean.
Market Researcher — tracks industry developments, synthesizes news and third-party research, and surfaces relevant signals. This is the most purely retrieval-based of the five research agents — and correspondingly the lowest-risk starting point for a team new to AI agents.
Finance and Operations Agents
Valuation Reviewer — checks valuation work against comparable methodology. This is a review layer, not a primary analysis layer — the agent validates that the approach is consistent and flags deviations from standard methodology.
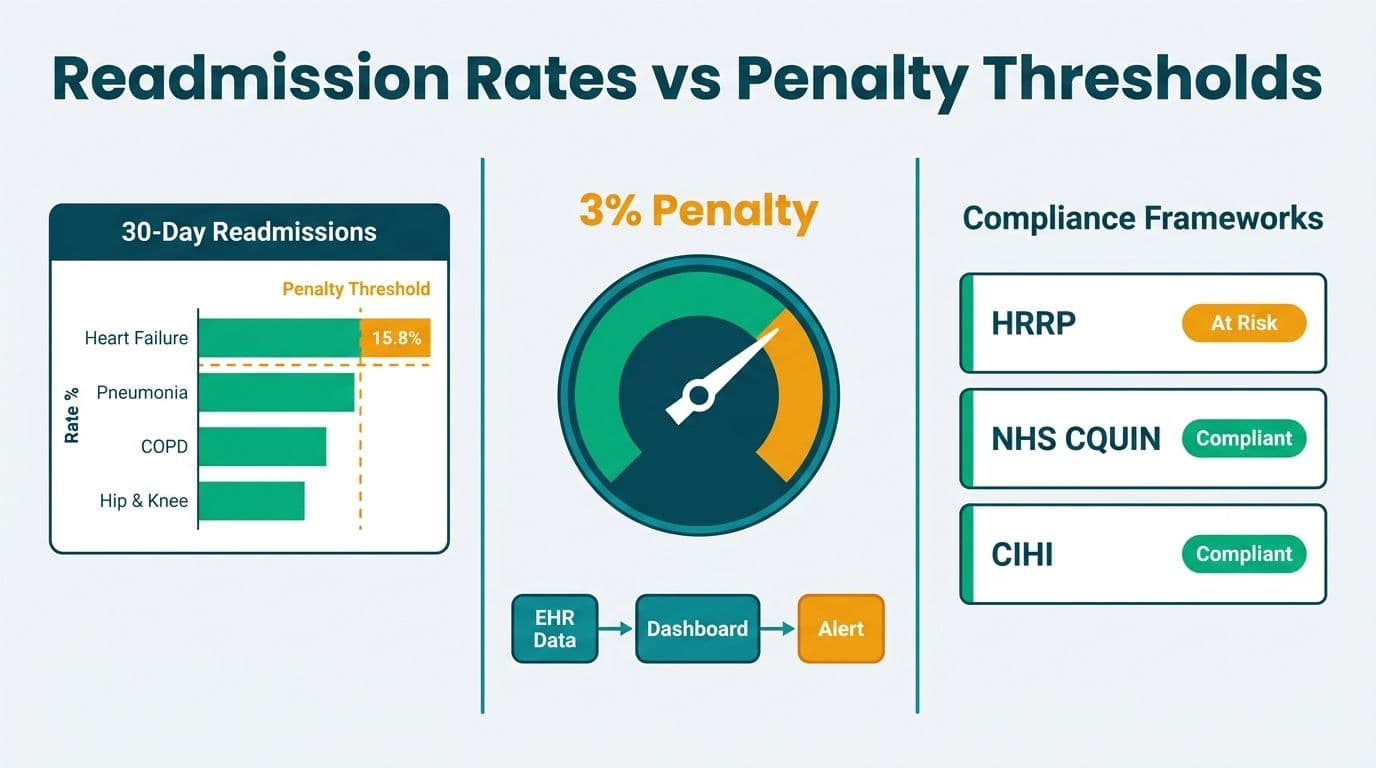
General Ledger Reconciler — reconciles accounts and runs NAV calculations. Manual GL reconciliation is one of the most time-intensive tasks in a finance team's month: matching every transaction in the general ledger against bank statements, invoices, sub-ledgers, and intercompany balances. APQC benchmarking puts median reconciliation time at six hours per cycle. For a three-person team at a $20–50 million revenue company, that can mean 50–80 person-hours per month on matching and exception resolution. Industry data shows 56% of financial institutions still rely on spreadsheets for reconciliation, and the IOFM documents a 3–5% error rate in manual processes. A 2023–2024 study across three US financial institutions found AI-powered reconciliation reduced error rates from 1.5% to 0.4% — meaningful at scale.
Month-End Closer — runs close checklists and prepares journal entries. A Ledge survey of 100 finance professionals found 50% of teams take more than five business days to close. Cross-departmental dependencies (cited by 56% of respondents), Excel-driven processes (50%), and legacy systems (40%) are the primary drags. The agent works through the structured checklist portion of close — the mechanical steps that eat hours but require no judgment. Andrea Ellis, CFO of Fanatics Betting & Gaming, described a comparable workflow: AP journal entry preparation that "used to take 20 hours during month-end close, and now takes just 2 hours each month."
Statement Auditor — reviews financial statements for consistency and audit-readiness. The agent checks for internal consistency — numbers that tie across schedules, footnotes that match the face of the statements — before the work goes to external auditors. It is a pre-audit quality control layer, not an audit replacement.
KYC Screener — assembles customer files, reviews documents, and packages escalations. US financial institutions spend an estimated $35–40 billion annually on AML operations. Under FINRA Rule 2090, the Patriot Act, and FinCEN requirements, institutions must establish customer identification programs, perform customer due diligence, and conduct enhanced due diligence for high-risk customers. The agent handles the research and aggregation work — compiling the file, checking it against known typologies — and surfaces highest-risk cases for human review. FIS's partnership with Anthropic for AML specifically is designed so that human investigators retain final approval authority on every case.
The 64% Benchmark Score: What It Actually Means
Anthropic's headline claim is that Claude Opus 4.7 scores 64.37% on Vals AI's Finance Agent benchmark — leading GPT-5.5 at 59.96% and Gemini 3.1 Pro at 59.72%. That number has been quoted widely. It deserves a closer read.
The Vals AI benchmark was developed in consultation with Stanford researchers and domain experts from Goldman Sachs, Silver Lake, and Citadel. It contains 537 questions across nine financial task categories, with a core focus on performing research on SEC filings — the foundational activity behind equity research, credit analysis, and investment due diligence.
The questions range from simple retrieval — "which geographic region has experienced the most revenue growth?" — to complex numerical reasoning requiring multi-document synthesis, such as calculating M&A firepower from a combination of financial schedules. Agents are given access to EDGAR search, Google search, document parsing, and retrieval tools, and are evaluated on accuracy, latency, and cost.
Here is what 64.37% means in practice: the model excels at simple quantitative and qualitative retrieval — tasks that are easy but time-intensive for human analysts — and fails on roughly 36% of the benchmark, concentrated in complex analysis, multi-document projection, and forward-looking reasoning.
The benchmark's own documentation is explicit about this: models "perform best on simple quantitative and qualitative retrieval tasks. These tasks are easy but time-intensive for finance analysts." The failure mode is not random — it clusters in exactly the tasks where errors are most consequential.
Wall Street Prep's 2026 testing of AI tools for financial modeling found that even the front-running tools "hallucinated significant portions of historical data" when asked to find data without being provided source documents. The practical implication: these agents perform best when given structured, verified source documents — and become unreliable when asked to retrieve historical data from memory or general search.
The Register summarized the tension cleanly: "64.37% is an industry-leading score despite a failure rate that would get a human tossed." That is not wrong. But it also misses the point of where these tools actually fit.
Anthropic's own Lisa Crofoot noted that Claude "could barely format a table without ref errors" less than a year ago. The benchmark documents "significant improvement over six months," which the authors frame as evidence that "the capability of LLMs to take on financial tasks is dramatically increasing." The 64% ceiling is the current state, not the destination.
The Market Reaction Was About Data, Not Agents
FactSet fell 8.1% intraday. Morningstar dropped more than 3%. The sell-off logic is worth examining, because it is more specific than "AI will replace financial research."
The thesis is about data terminals. FactSet, Morningstar, S&P Global, and Moody's make money selling structured access to financial data — the underlying raw material that analysts need to build models, run comps, and write research. Anthropic's eight new data connectors and Moody's own MCP app covering 600+ million companies suggest a world where an AI agent pulls that data directly into a workflow without a human opening a terminal.
The irony worth noting: Morningstar's own CTO, Adam Wheat, provided a testimonial for the Anthropic finance agent announcement, saying users get "faster answers and better ones." The company was simultaneously being sold off by investors who read the same announcement as a threat to its business model.
Gartner projects that by 2027, up to 90% of what-happened and why-it-happened analysis in finance will be fully automated. By 2029, CFOs who implement strategic AI deployment will add 10 margin points of growth. The data terminal business exists precisely to answer those questions — and the answer to who captures that margin is genuinely unclear.
What Still Legally Requires a Human
The most important section of Anthropic's announcement received the least coverage: "Users stay firmly in the loop — reviewing, iterating on, and approving Claude's work before it goes to a client, gets filed, or is acted on."
That is not a product limitation hedged with a legal disclaimer. It reflects a genuine set of legal requirements that have not changed and will not change with this product release.
Audit opinion letters — must be signed by a licensed CPA or audit partner. No AI can sign an audit opinion. The PCAOB's Technology Assisted Analysis standard (effective December 15, 2025, amending AS 1105 and AS 2301) clarifies auditors' responsibilities when using AI-powered data analysis tools, but the sign-off is still human. PCAOB audit documentation requirements under AS 1215 require evidence of who performed the work, who reviewed it, and the date of review.
CEO and CFO financial statement certifications — under Sarbanes-Oxley Sections 302 and 906, the CEO and CFO must personally certify the accuracy of financial statements. That certification cannot be delegated to an AI agent. The human at the top of the organization is legally on the hook for what the AI produced.
Suspicious Activity Reports — under the Bank Secrecy Act, SAR filing decisions require human investigator sign-off. The FIS-Anthropic AML agent is explicitly designed so that the AI assembles the evidence and humans make the call. BMO and Amalgamated Bank are early deployers; general availability is H2 2026.
Enhanced Due Diligence determinations — for high-risk KYC cases, EDD decisions are human decisions. The agent assembles the file; a human makes the compliance determination.
The Cambridge Centre for Alternative Finance's 2026 Global AI in Financial Services Report found that 70% of industry firms and 70% of regulators cite model hallucinations and unreliable outputs as a top-two risk. Regulators are watching closely: 42% reference the EU AI Act in their frameworks, 78% rate explainability as critical or important, and 60% of traditional financial institutions report concern about loss of human oversight.
PCAOB board member Christina Ho has described AI as a potential "engine that catalyzes innovation in public company auditing" — but PCAOB inspection priorities for 2025 explicitly include audit areas with increased use of technology, including generative AI. The regulatory posture is engaged, not permissive.
The Adoption Numbers Behind the Hype
The finance function's relationship with AI is further along than most headlines suggest — and further behind most vendor pitches.
Gartner's September 2024 survey projected that 90% of finance functions would deploy at least one AI-enabled technology by 2026. Their November 2025 follow-up found AI adoption in finance holding steady at 59% — meaningful penetration, but well short of the 90% projection. A separate Gartner survey found 57% of finance teams implementing or planning agentic AI as of October 2025.
The gap between intent and value is the more revealing number. Deloitte's Q4 2025 CFO Signals Survey — covering 200 CFOs at companies with more than $1 billion in revenue — found that 87% expect AI to be extremely or very important to their finance department in 2026. Only 21% of active users say AI has delivered clear, measurable value. 54% name integrating AI agents into finance as a top transformation priority. But 49% cite "freeing employees for higher-value work" as their top talent priority — a sign that most organizations are still thinking about AI as productivity enhancement, not workforce reduction.
That framing is supported by on-the-ground evidence. Jason Whiting, CFO of Mercury Financial, described the reality: "Across the board, the biggest benefit has been the ability to increase speed of analysis. Gen AI hasn't replaced anything, but it has made our existing processes and people better."
The Cambridge CCAF report adds an important counterweight to displacement anxiety: only 24% of financial services firms expect a net reduction in jobs from AI. The dominant expectation is redeployment, not replacement.
The Forward-Deployed Engineer Problem
The least-covered aspect of the Anthropic finance agents launch was the implementation gap. CIO.com interviewed enterprise AI analysts who identified a structural bottleneck that no benchmark score addresses.
Gartner analyst Alex Coqueiro warned that "70% of enterprises will be forced to abandon agentic AI solutions from forward-deployed engineer engagements because of high vendor costs and lack of internal skills to evolve them independently."
Enterprise AI analyst Sanchit Vir Gogia was more direct: "Large enterprises are not collections of clean tasks waiting to be automated. They are collections of exceptions, legacy systems, fragile integrations, access controls, undocumented workarounds, compliance obligations, and human judgment pretending to be process."
The ten agent templates are starting points — workflow scaffolding built for a reasonably clean environment. Every real finance team has the FactSet login that only works on certain machines, the Excel model that someone built in 2019 that nobody fully understands, the reconciliation exception that gets handled differently every month because of a vendor that never fixed their data format.
Banking technology specialist Nik Kale framed the test that matters: "After the forward-deployed team leaves, can your organization still operate, monitor, challenge, and safely modify the agentic workflow?"
That is a question about organizational capability, not model capability. And it is the question most organizations are not yet ready to answer.
What This Means for a SaaS Finance Team
If you are a CFO or Director of FP&A at a SaaS company in the 50–500 employee range, here is the honest assessment of where these agents fit into your 2026 roadmap.
Where you can move immediately — the Meeting Preparer and Market Researcher agents are low-risk starting points. The tasks are well-defined, the failure modes are visible, and a wrong answer is caught before it causes damage. If you are already using Claude for research and synthesis, these agents add workflow structure without introducing new risk.
Where you should pilot carefully — the Month-End Closer and GL Reconciler agents address real pain points. If 50% of finance teams take more than five business days to close, and your team is in that half, the mechanical checklist work is worth automating. But the agent needs clean data pipelines, documented exceptions, and a human reviewing the output before journal entries are posted. A 0.4% error rate sounds excellent — on a $10 million payables ledger, it still represents $40,000 in potential discrepancies.
Where you should wait — Statement Auditor and the Earnings Reviewer for high-stakes filings should stay in human hands until your team has significant experience with how the agents fail in your specific data environment. The 36% failure rate on complex analysis is not uniformly distributed — it concentrates in exactly the multi-document, cross-period reasoning that matters most in external reporting.
The most important thing you can do before deploying any of these agents is the same thing that makes Copilot for Power BI work: clean up your data model. Wall Street Prep's 2026 testing found that every AI tool — including the front-runners — hallucinated historical data when asked to retrieve it without source documents. Agents that work against structured, verified, well-described data sources perform dramatically better than agents working against the typical enterprise data environment.
The Bigger Picture: Infrastructure and Reliability
The finance agents announcement landed one day before Anthropic announced it was renting SpaceX's Colossus 1 data center in Memphis — 300 megawatts and 220,000-plus NVIDIA GPUs — as a bridge while its larger compute agreements with Amazon (5 gigawatts) and Google and Broadcom (5 gigawatts beginning 2027) ramp up.
The compute story matters for finance teams evaluating AI tools on a multi-year horizon. Anthropic grew 80x last quarter by its own account — a growth rate that creates infrastructure strain and, if unaddressed, the kind of availability and rate-limit problems that make enterprise adoption difficult. Doubling Claude Code's rate limits and eliminating peak-hours throttling are direct responses to that strain.
Marco Argenti, CIO of Goldman Sachs, described the current moment with a framing that applies directly to SaaS finance: "This is the first time that instead of buying infrastructure, you can actually buy intelligence." The question for any finance leader is not whether to engage with that shift but how to engage with it in a way that preserves the accuracy, auditability, and accountability that financial reporting requires.
Anthropic's own Chief Economist, Peter McCrory, projects that current-generation AI models could add 1.8 percentage points per year to US labor productivity over the next decade — roughly doubling recent growth rates. Dario Amodei, Anthropic's CEO, acknowledged the uncertainty plainly when asked about the employment impact at the New York briefing: "The cone is even wider than I thought. I don't think anyone knows."
That honesty is worth sitting with. These tools are genuinely capable, improving rapidly, and creating real productivity gains for the teams deploying them carefully. They are also operating in a regulatory environment that has not finished deciding what AI-assisted financial work is allowed to look like, and in a data environment — the typical enterprise's — that was not built for them.
Where We Come In
Lets Viz runs Managed Power BI for SaaS finance teams — SLA-backed refresh monitoring, a documented hours bank for model work, and strategic BI advisory that includes AI governance as a first-class deliverable.
The finance agents Anthropic shipped this week do not replace a well-governed Power BI environment. They depend on one. An agent that reads a financial model and runs comparable analysis is only as reliable as the data model underneath it — the same data model that determines whether your CFO walks into Monday with numbers she can trust.
If you are evaluating AI agents for your finance team and you want a partner who will tell you honestly where the data foundation needs work before the agents go live, we should talk.