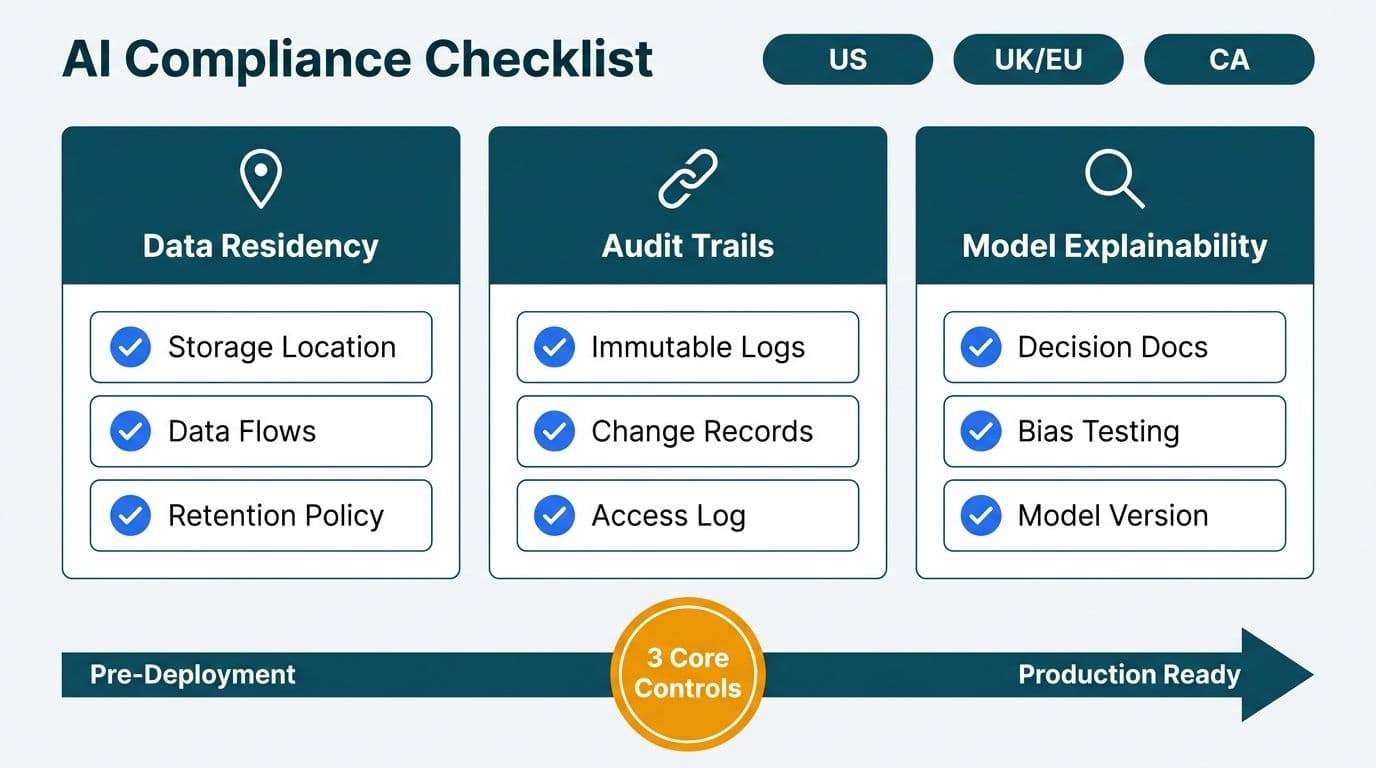
AI + ARR waterfalls: what works, what still needs a human

Every SaaS CFO has stared at the same six bars: Starting ARR, New, Expansion, Contraction, Churn, Ending ARR. No other chart gets this much executive attention per pixel. So when a vendor says 'AI can build this for you', finance leaders rightly want to know - at which step does it help, and at which step does it quietly make things worse?
We ran the same realistic SaaS P&L from our Copilot for Power BI test through the ARR waterfall workflow end-to-end. This is what AI handled well, where it broke, and the three rules we'd give any FP&A team before they let AI near this chart.
The short version
AI is genuinely useful for assembling the waterfall - pulling the right records into the right buckets. It is unreliable at classifying edge cases - reactivations, mid-cycle contractions, migrations, annual-to-monthly plan changes. And it is dangerous at explaining the waterfall - writing the narrative that goes to the board.
The finance teams who get real value from AI here are the ones who know exactly which of the three they're using it for.
Step 1 - Classifying movements into buckets (mostly safe)
The first job in building an ARR waterfall is classifying every movement in the period: is this customer a new logo, an expansion, a contraction, or a churn? For a simple SaaS business with clean billing, AI is reliably good at this. Give it the subscription table and the last-period ARR snapshot, and it will correctly bucket the majority of accounts.
Where it slipped in our test: edge cases that require business judgment. A customer who churned in February and came back in March was classified three different ways across three runs - sometimes as expansion (wrong), sometimes as new logo (also wrong), and occasionally as reactivation (correct). A customer who migrated from annual billing to monthly at a lower effective rate was classified as contraction by the AI, when our accounting policy treats it as neutral.
The takeaway: AI gets 80-90% of the bucketing right. The 10-20% it gets wrong are exactly the cases that matter most for explaining the number.
Which ARR bridge calculations can AI handle - and where must a human stay?
Not all ARR movements are equally hard to classify. The contract structure underneath each movement determines whether AI can handle it safely or whether a human must stay in the loop. This question sits at the center of every SaaS finance team evaluating an AI ARR waterfall in Power BI: not whether AI helps, but precisely where the line is.
Where AI is reliable: simple monthly contracts. When a customer is on a flat monthly plan with a clear start date, a clear cancellation date, and no mid-cycle changes, the bucketing logic is unambiguous. New customer in March, gone in July: new logo in March, churn in July. No policy call required. AI handles this reliably at scale, and it is where most of the volume sits for high-velocity SMB SaaS.
Where humans stay mandatory: multi-year contracts. A three-year deal with an annual true-up, a ramp structure in year two, and a price escalator in year three is not a data problem - it is a revenue recognition problem. ASC 606 and IFRS 15 both require judgment calls about when ARR is recognizable and how contract modifications affect the waterfall. AI will produce an answer; it will simply not apply your recognition policy consistently, because that policy lives in your controller's head, not in the billing export.
Where humans stay mandatory: recognition timing. Even for straightforward annual contracts, the question of when a renewal counts as expansion versus continuation depends on how your team defines the measurement window. AI tools infer a definition from the data and apply it consistently within a single run - but that definition may not match the one your auditors agreed to last quarter.
Where humans stay mandatory: churn cohort attribution. When a customer who churned fourteen months ago returns at a higher ARR, your waterfall must decide - new logo or reactivation, and which cohort gets credit? This is policy, not data. AI will make a call, but it will not know whether your board agreed last year to treat all reactivations over twelve months as new logos. That institutional memory has to come from a human.
The practical dividing line: AI handles the ARR bridge reliably when the contract is simple, the period is monthly, and no recognition judgment is required. Add multi-year terms, mid-contract modifications, or cohort attribution rules, and human review becomes mandatory before the number goes anywhere near a board pack.
Step 2 - Summing and rendering the waterfall (safe)
Once the records are bucketed, the math is arithmetic: sum up New, Expansion, Contraction, Churn, and you have your waterfall. Copilot writes this part of a Power BI report reliably. Measures compile, the bars render, the total reconciles to Ending ARR.
There is one foot-gun: if the AI is also the one that did the bucketing in step one, the sums look reconciled but the underlying classifications are wrong. The total is right because errors cancel - a reactivation wrongly booked as a new logo adds to New and doesn't subtract from Contraction, but the total is unchanged. The board sees a clean waterfall that hides a classification problem.
The discipline: always validate the classification step independently of the summing step. Reconciling totals proves only that the math added up, not that each record landed in the right bucket.
Step 3 - Explaining the waterfall (dangerous)
This is where we've seen the most harm done. Every AI narrative feature we tested - Copilot's auto-summary, generic LLM prompts over the data, chat-style Q&A - is confidently and consistently wrong at explaining why a waterfall moved the way it did.
In our test, a contraction that was driven by a single enterprise customer moving from Pro to Starter was described by Copilot as 'continued softness in the mid-market segment.' An expansion that came entirely from one customer adding seats at renewal was narrated as 'healthy growth across the customer base.' Neither was true. Both sounded like things a CFO has read before.
This pattern - causal claims that sound plausible because they match the shape of things CFOs have seen before - is the single biggest risk of AI in the monthly board prep. The narrative reads well, so it rarely gets challenged.
The three rules for AI on the ARR waterfall
Rule 1 - Always reconcile classification to a known prior. Before trusting an AI-assembled waterfall, pick 10 random accounts, look up their movement manually, and verify the AI bucketed each one correctly. If the error rate is above one in ten on this sample, the waterfall is not ready for a board pack.
Rule 2 - Separate the bucketing model from the summing model. Use AI for the arithmetic and rendering step, but keep the classification step governed by an auditable rules set (either hand-written or a heavily-tested mapping table). This lets you trace any waterfall number back to the specific business rule that produced it.
Rule 3 - Never let AI write the causal narrative unchallenged. If your process is 'Copilot writes it, we send it,' you will eventually mislead a board. Require an FP&A analyst to rewrite the 'why' sentences before the deck leaves the team. The AI-written draft saves time on structure and word choice - not on diagnosis.
The practical recipe
The setup that holds up in production looks like this:
A governed bucketing table (hand-maintained or AI-assisted but human-reviewed) that maps each customer-movement event to the right waterfall bucket.
A Power BI measure set (AI-authored is fine) that sums the buckets into the standard six-bar waterfall.
A shadow-run period of at least one quarter, where every AI output is paired with an analyst-produced output, and the deltas are logged and investigated.
A narrative workflow where AI produces a first draft of the commentary, and an analyst rewrites every causal claim before the deck ships.
Where we come in
Lets Viz runs Managed Power BI for SaaS finance teams. Governed bucketing, SLA-backed refresh monitoring, AI governance as part of the service - exactly so your ARR waterfall doesn't become the thing that misleads the board.
If you're wiring AI into your month-end close and want a partner who has already stress-tested the common failure modes, we should talk.